





postMessage is the most common way to send data between multiple worker threads in JavaScript, and in Bun v1.2.21, postMessage(string) performance is nearly independent of string size. This is a big improvement for multi-threaded JavaScript servers & CLIs.
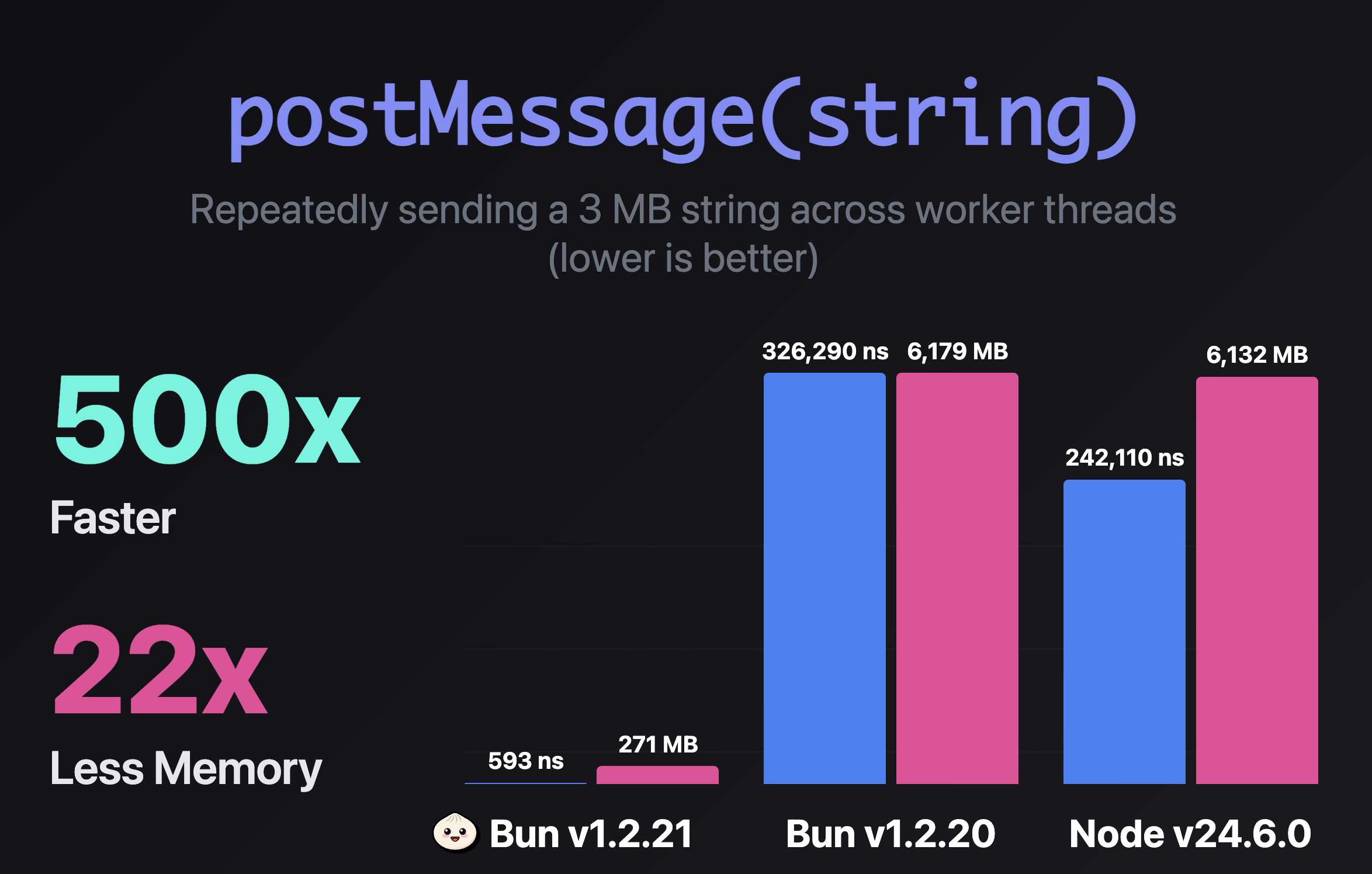
By avoiding serialization for strings we know are safe to share across threads, it's up to 500x faster and uses ~22x less peak memory in this benchmark.
| String Size | Bun 1.2.21 | Bun 1.2.20 | Node 24.6.0 |
|---|---|---|---|
| 11 chars | 543 ns | 598 ns | 806 ns |
| 14 KB | 460 ns | 1,350 ns | 1,220 ns |
| 3 MB | 593 ns | 326,290 ns | 242,110 ns |
The optimization kicks in automatically when you send strings between workers:
// Common pattern: sending JSON between workers
const response = await fetch("https://api.example.com/data");
const json = await response.text();
postMessage(json); // Now 500x faster for large strings
This is particularly useful for applications that pass large JSON payloads between workers, like API servers, data processing pipelines, and real-time applications.
How we did this in JavaScriptCore
Want to know the technical details? Keep reading for a deep dive into how we optimized string handling in WebKit's JavaScript engine.
The key insight
postMessage typically uses the Structured Clone Algorithm to serialize data before sending it to another thread. This means copying every byte of your string into a new buffer, then deserializing it on the other side.
But here's the thing: in JavaScriptCore (the engine Bun uses), strings are already thread-safe reference-counted objects. The string data itself is immutable after creation, and the reference count uses std::atomic:
class StringImplShape {
std::atomic<unsigned> m_refCount; // Thread-safe!
unsigned m_length; // Immutable
union {
const LChar* m_data8; // Immutable
const char16_t* m_data16; // Immutable
};
mutable unsigned m_hashAndFlags; // The only mutable part
};
So if strings are already thread-safe, why serialize them at all when sending between threads in the same process?
Finding the fast path
Not all strings can be safely shared. We identified three types that need serialization:
- Atom strings - Thread-local property names and symbols
- Substrings - Point to other strings with complex lifetimes
- Rope strings - Created by operations like
"foo" + "bar"or.slice()
For everything else, we can skip serialization entirely. We just need to ensure the lazily-computed hash value is calculated before sharing (since that's the only mutable part):
WTF::String toCrossThreadShareable(WTF::String& string)
{
auto* impl = string.impl();
// Can't share atoms, symbols, or substrings
if (impl->isAtom() || impl->isSymbol() ||
impl->bufferOwnership() == StringImpl::BufferSubstring)
return string.isolatedCopy();
// Force hash computation before sharing
impl->hash();
// Prevent this thread from atomizing.
impl->setNeverAtomicize();
return string; // Share the pointer directly!
}
The fast path conditions
The optimization applies when:
- You're using
postMessageorstructuredClone - You're sending only a string (not mixed data)
- The string isn't a substring, rope, atom, or symbol
- You're sending to another thread in the same process
- The string.length >= 256 characters
This covers the extremely common pattern of sending strings between workers, which is why the performance improvement is so dramatic.
What's next
We could expand this optimization to include string values within objects and arrays, but a 500x speedup for one of the most common worker communication patterns is a great start. The same approach could potentially apply to other immutable data types in the future.